こんにちは。DevRelチームのmoriとhirokiです。
DevRelメンバーが生成AIに興味があって、試してみたいねーと話していたところ良い記事を見つけたので参考に構築してみることにしました!
先日の「Gartner、「日本における未来志向型インフラ・テクノロジのハイプ・サイクル:2024年」を発表」の記事でも「RAG」は過度な期待のピーク期に位置付けた今注目の技術として取り上げられてました。
今回はタイトルにあります通り、Amazon Bedrockを使用してRAGを構築してみましたのでその過程をブログに残します。
いきなり難しいことも出来ないので、簡単なところで自社の情報を取り込んでそれに関する質問をして回答が返ってくるよねって検証をしてみました。
参考にしたサイト

参考にさせていただきました。ありがとうございます。
利用するデータ
今回は自社で作成した会社紹介のPDFファイルを使用してみます。
中身は30P近くあるので全ては載せられないので、参考に何枚か貼ります。

いざ構築!
まずは準備でS3バケットを作成
今回は生成AIに取り込む情報をS3に置くのでS3バケットを作成していきます。
リージョンは「us-east-1(バージニア北部)」で作ります。
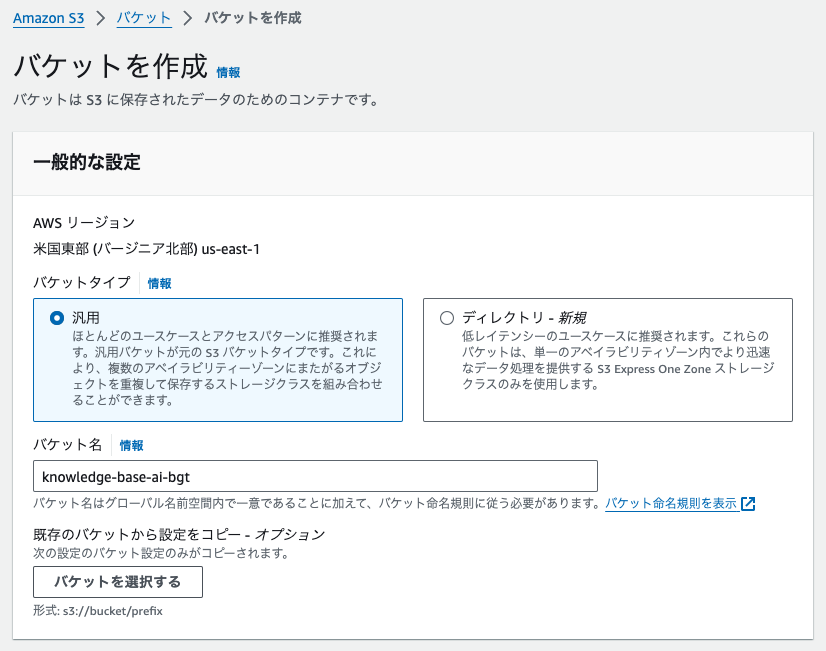
その他の設定はデフォルトのままで作成しました。
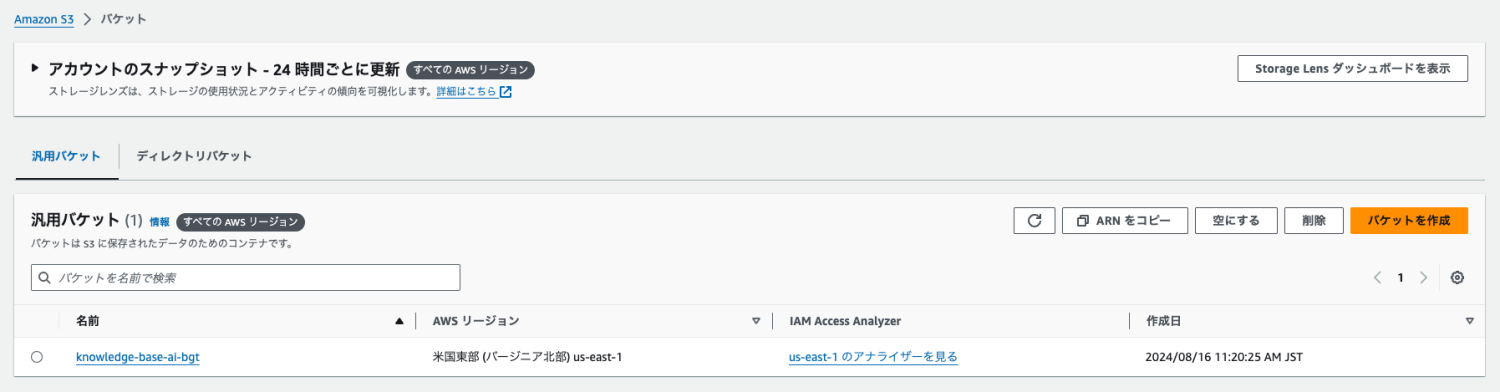
こちらのバケットに会社紹介のPDFをアップロードしておきます。
次にAmazon Bedrockを構築してみます
モデルアクセス管理を設定
Amazon Bedrockのページを開いて、使用を開始をクリック

モデルアクセスを管理をクリック
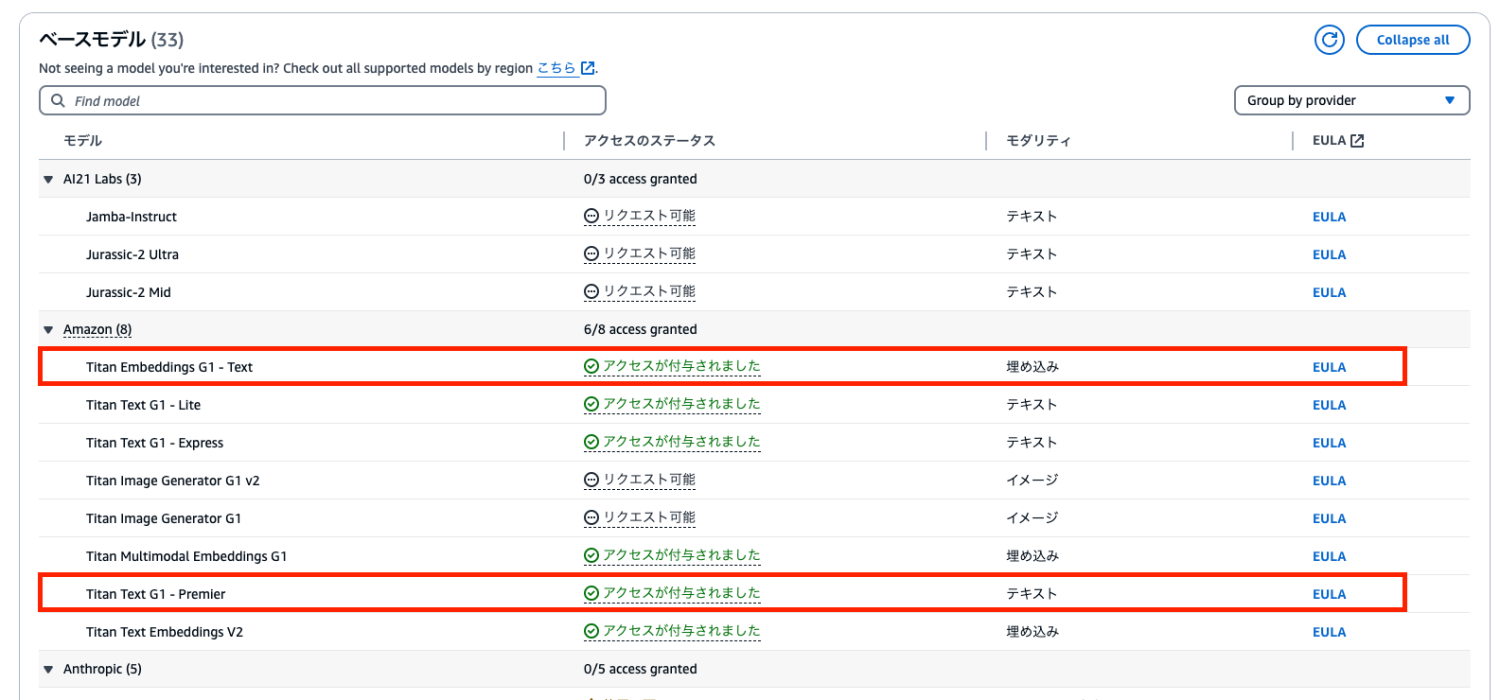
すでにアクセス付与を設定していますが今回使った「Titan Embeddings G1 - Text」と「Titan Text G1 - Premier」にアクセス権を付与しておきます。
ナレッジベースを作成
左メニューのナレッジベースをクリック

ナレッジベースを作成をクリック
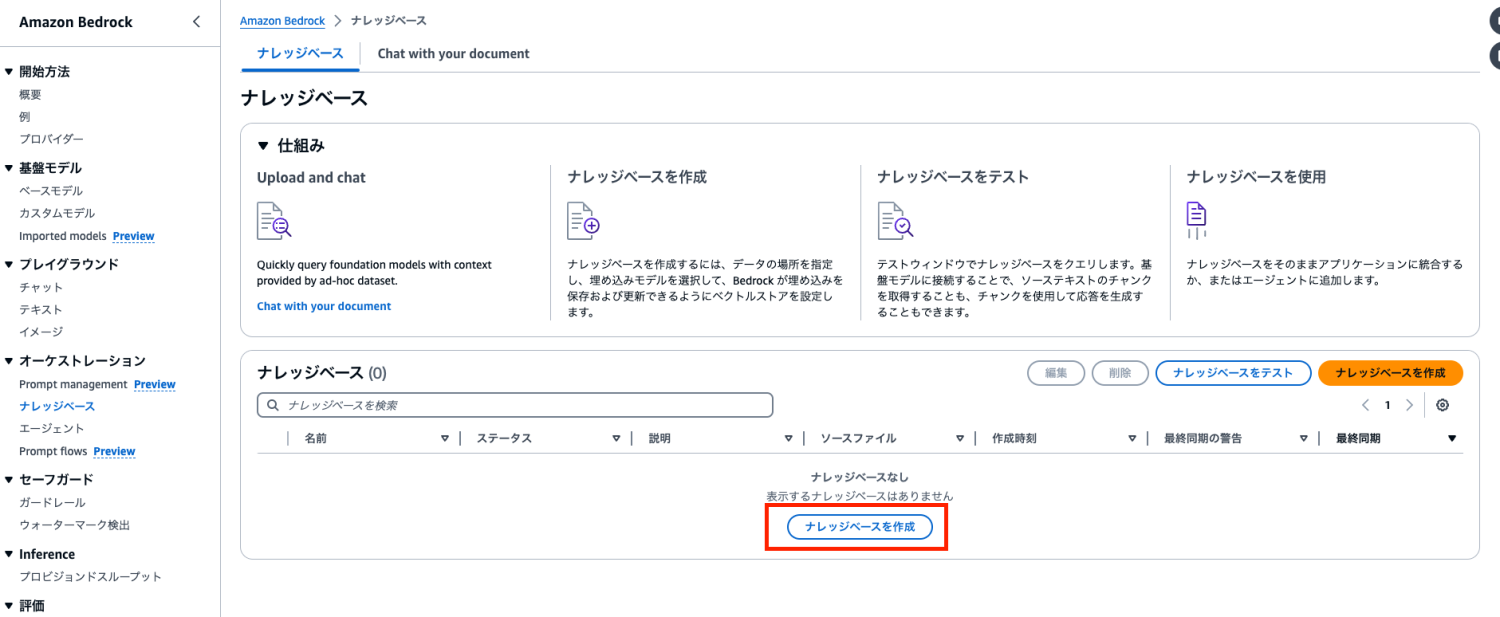
ナレッジベース名を入力、IAM許可で新しいサービスロースを作成して使用を選択してサービスロール名を入力します。
データソースはS3を選択して次へをクリックします。
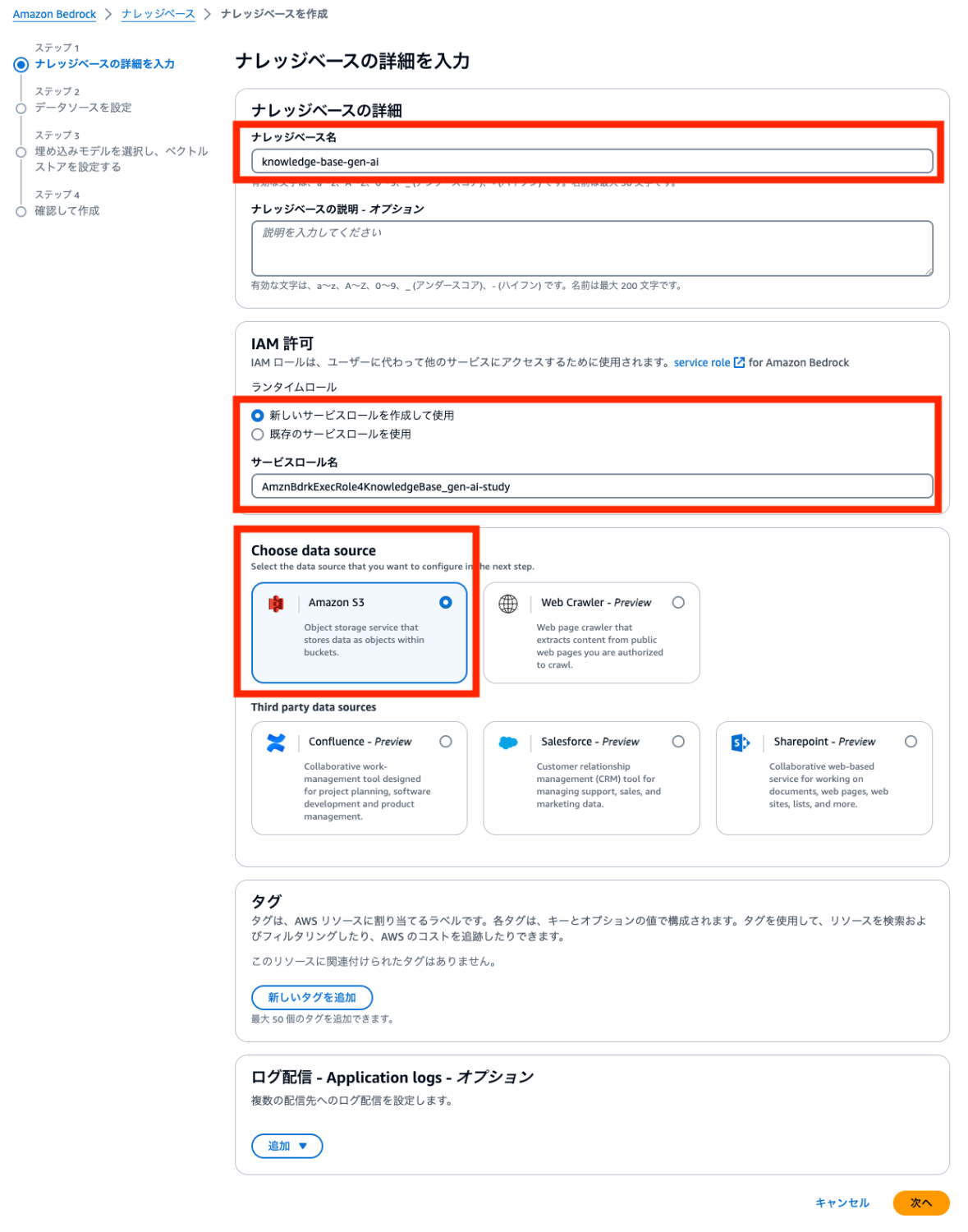
データソース名を入力し、S3を先程作成したバケットを指定して次へをクリックします。
その他の設定はデフォルトのままにしています。
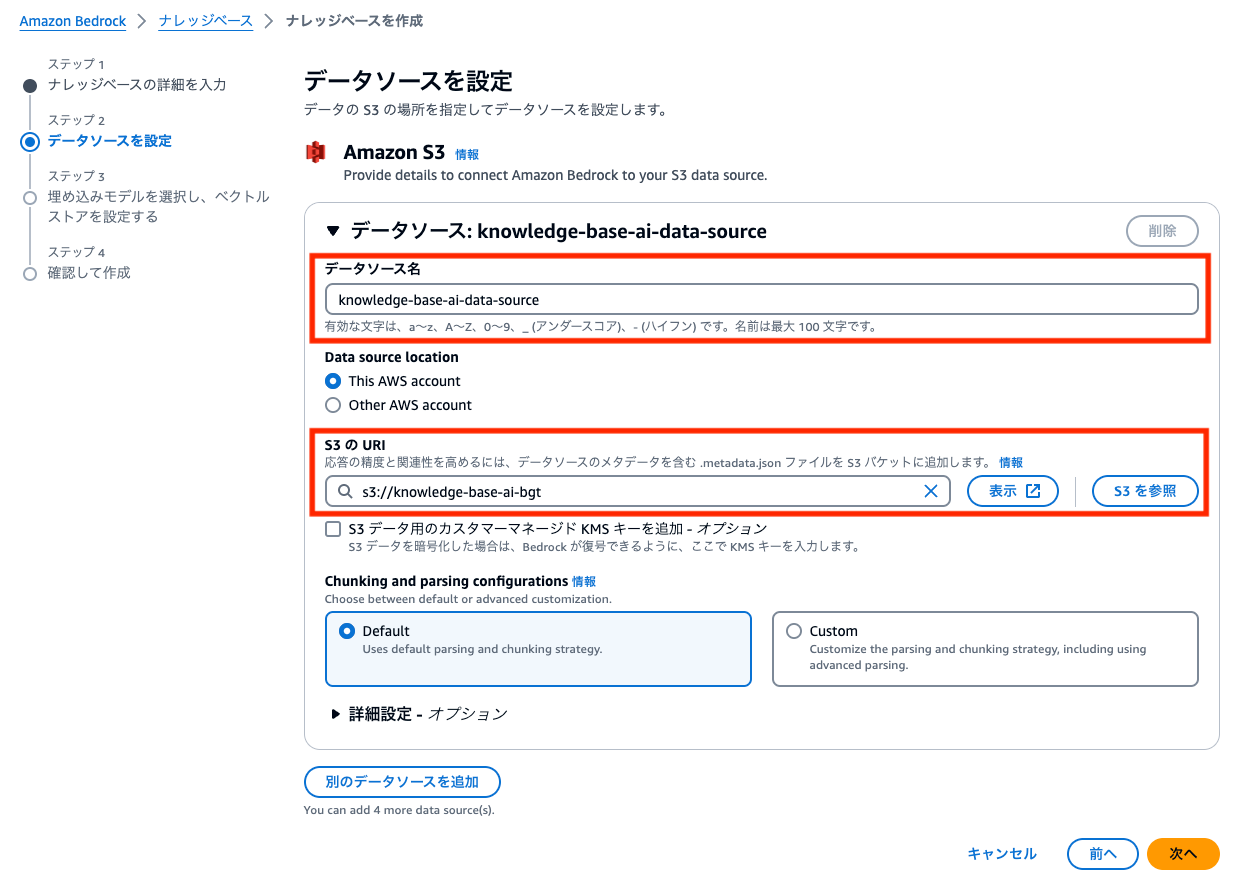
埋め込みモデルに先程アクセス権限を許可した「Titan Embeddings G1 - Text v1.2」を選択し、次へをクリックします。
その他の設定はデフォルトのままにしてます。
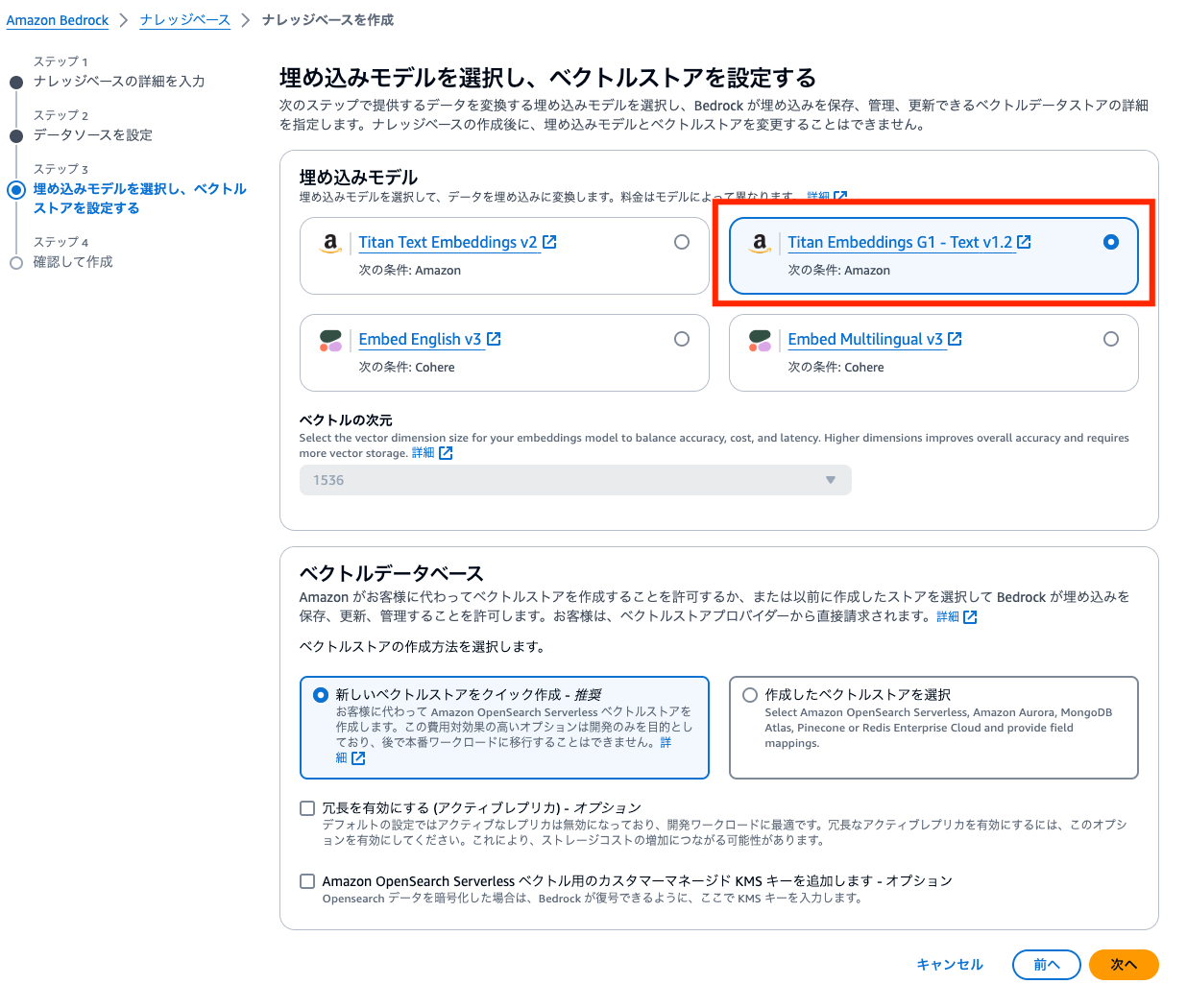
内容を確認して「ナレッジベースを作成」をクリックします。
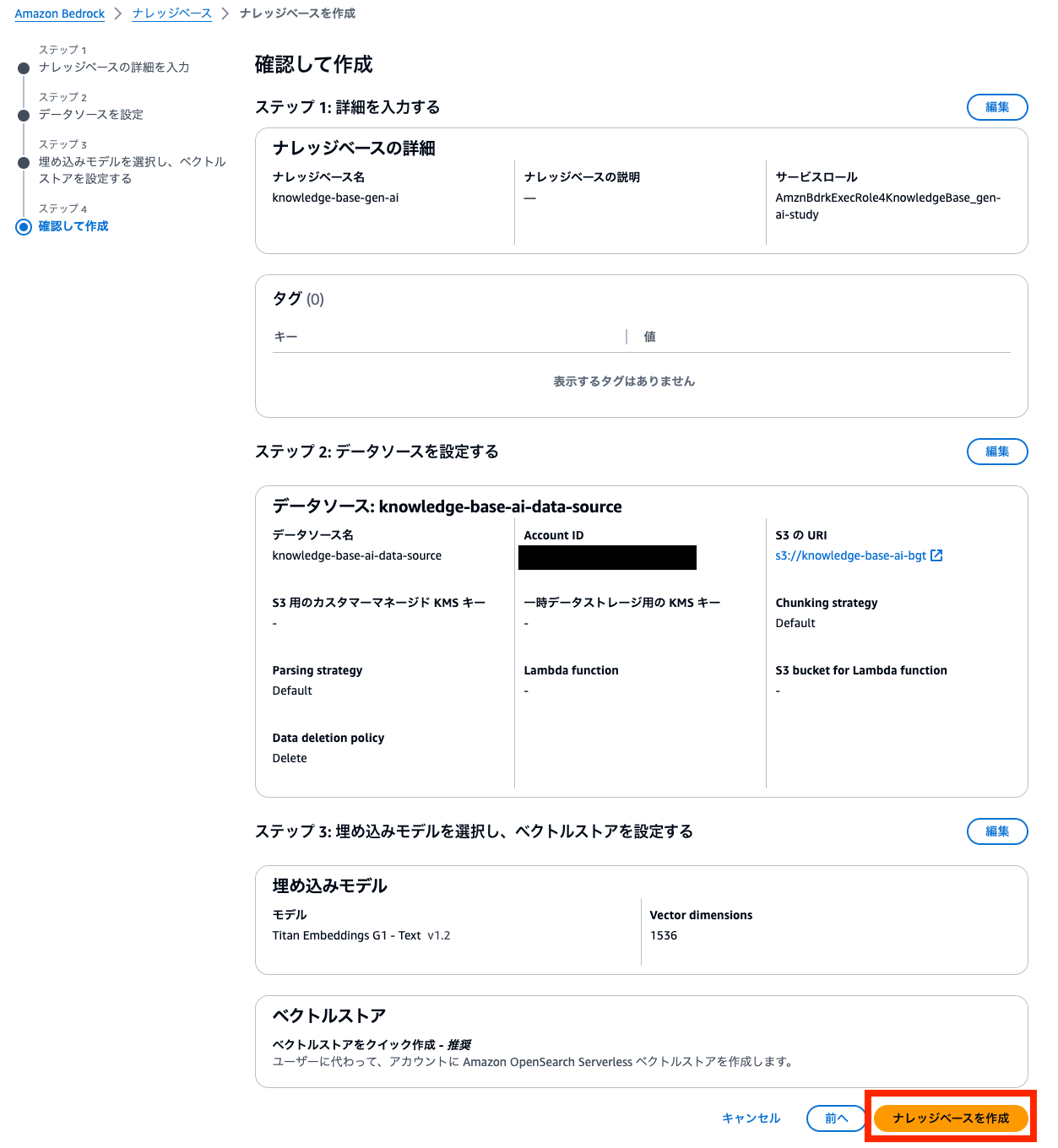
作成までにある程度時間がかかりました。
作成が完了すると、ナレッジベースの詳細が表示されるページに飛びます。
これで構築は完了です!
質問してみる
作成が完了すると下記の画面になりますのでモデルを選択します。
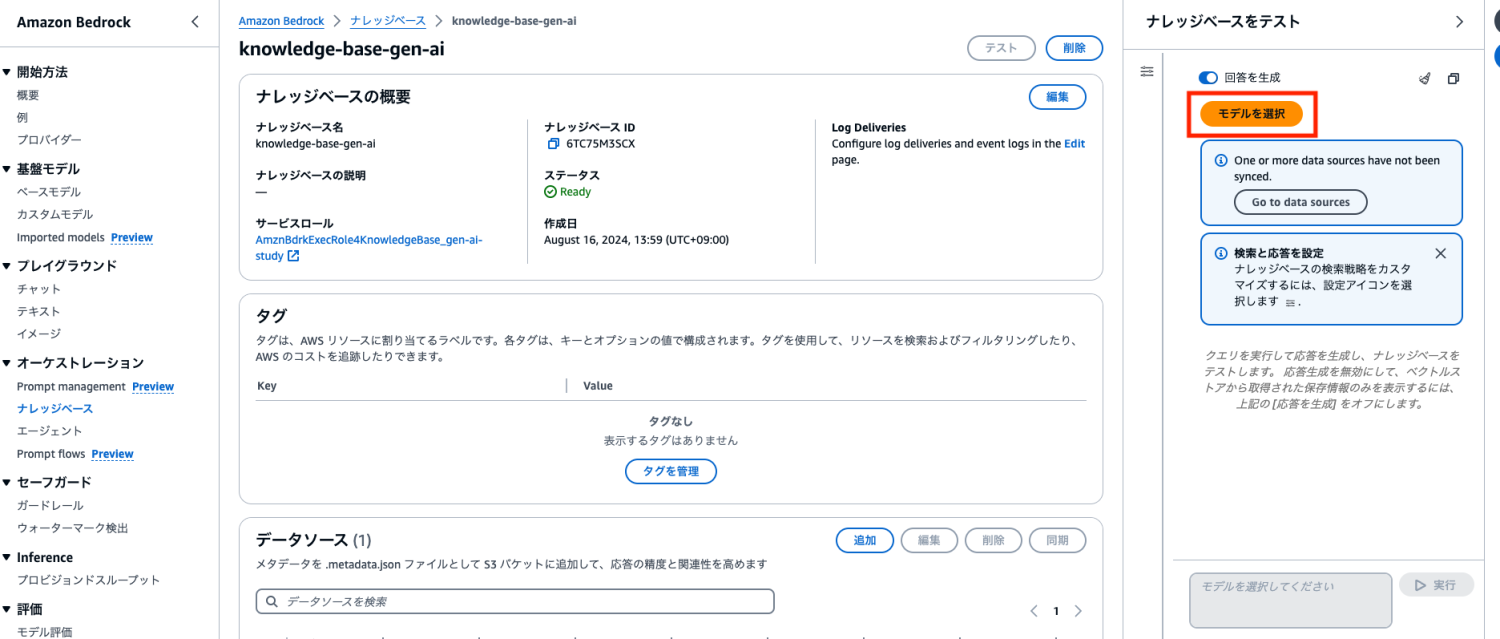
Titan Text G1 - Premierを選択して適用をクリックします。
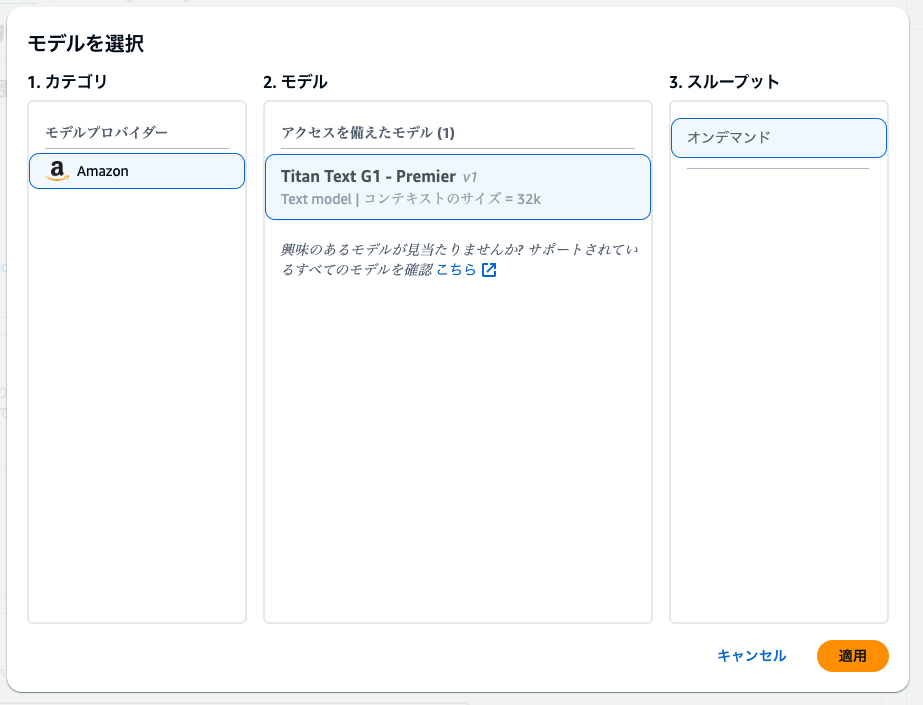
「One or more data sources have not been synced.」と表示されているのでデータソースを同期します。
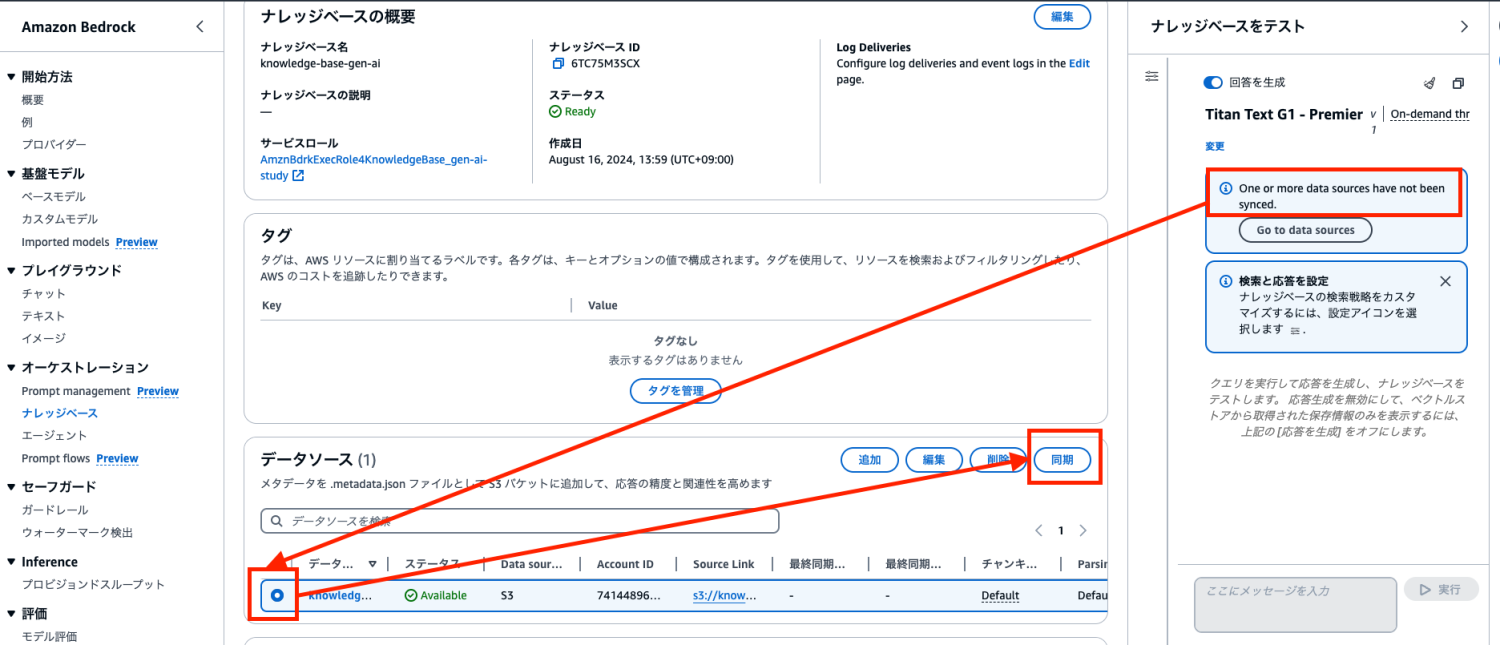
同期が完了すると「ナレッジベースをテスト」の箇所のメッセージ入力ができるようになるので、自社の事を質問してみます。
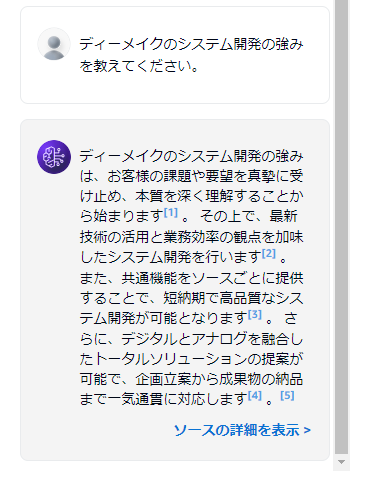
こんな感じでちゃんと答えてくれますね。
というところで今回はここまで。
他にもいくつか質問してみましたが、期待した答えが返ってこない場合も多々ありました。
おそらく準備したデータの問題、チャンクサイズをはじめとしたパラメータの設定など調整が必要であると思いました。
次は効率の良いデータの作成・チューニング方法を学んでより正確な回答を導き出せるようにしてみたいですね。
おまけ
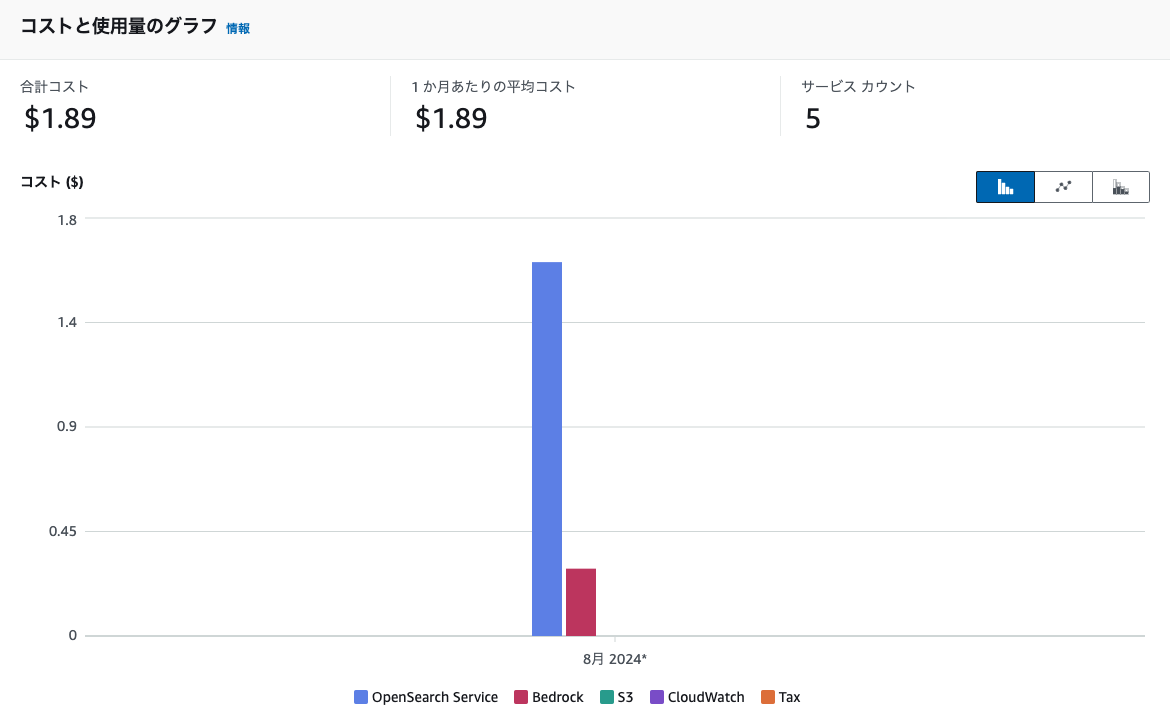
今回の検証にかかったコストは下記の通りでした。
検証の数時間と数M程度のデータでしたので少額で試すことができました。
OpenSearch Serviceはナレッジベースのベクトルデータベースに利用されますが、データ量によっては高額になりそうなのでご注意ください。